目标该怎么管理?静态还是动态发现?
目标管理是使用静态还是动态发现,这个和基础架构有关,要回答这个问题,需要先说说应用部署的现状!
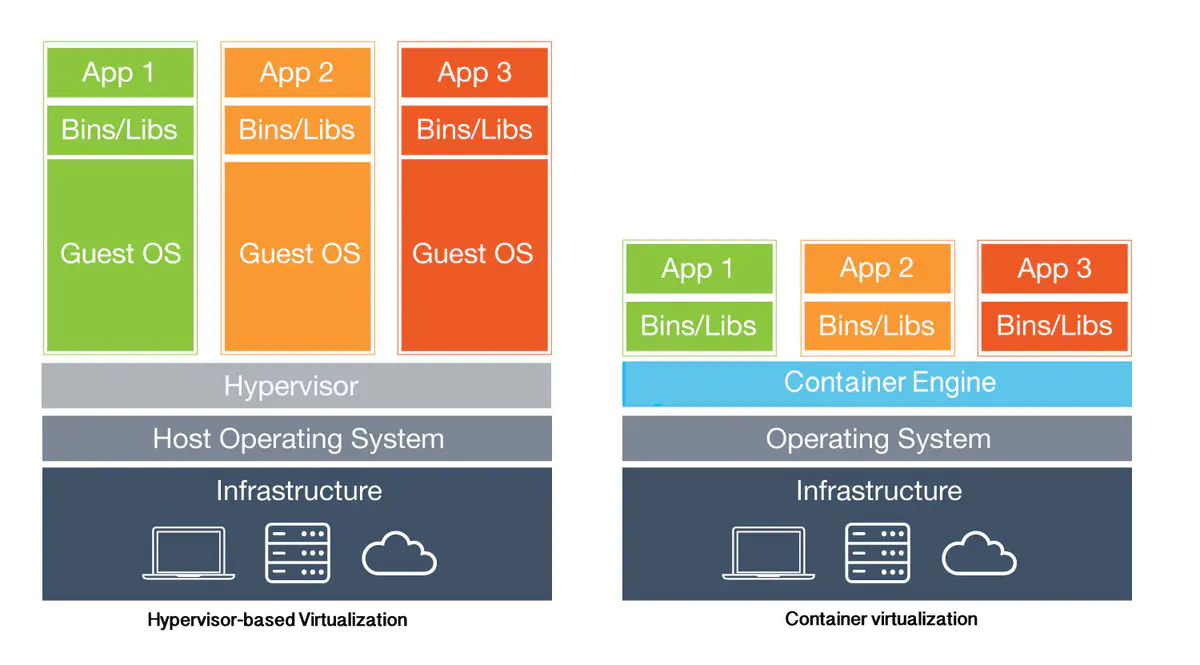
目前,企业应用部署有两种选项:
- 基于虚拟机
- 基于容器
当然,更多的是虚拟机里装docker,算是两者的结合,节省成本。
那么基于虚拟机部署应用有什么特点呢?就是变化小,你的预期和实际情况是相对静止的,在虚拟机上部署一套应用,一套流程走下来,大概得小半天吧,这种情况把要监控的目标写到Prometheus的配置文件,再重启Prometheus server,完全玩得转!
然而,当公司的应用开始基于容器部署,特别是管控平面使用了k8s,那么手动配置Prometheus、重启就成为了噩梦一样的存在!运维会疲于奔命,开发会吐槽运维。
所以监控目标的配置,取决于使用的底层技术!
题外话:要想Devops在企业落地,得有一整套配套的工具,整体打通。
那么Prometheus在抓取目标方面是怎么做的呢?我们先重温一下相关组件的启动:
{
// Scrape discovery manager.
g.Add(
func() error {
err := discoveryManagerScrape.Run()
level.Info(logger).Log("msg", "Scrape discovery manager stopped")
return err
},
func(err error) {
level.Info(logger).Log("msg", "Stopping scrape discovery manager...")
cancelScrape()
},
)
}
{
// Notify discovery manager.
...
}
{
// Scrape manager.
g.Add(
func() error {
// When the scrape manager receives a new targets list
// it needs to read a valid config for each job.
// It depends on the config being in sync with the discovery manager so
// we wait until the config is fully loaded.
<-reloadReady.C
err := scrapeManager.Run(discoveryManagerScrape.SyncCh())
level.Info(logger).Log("msg", "Scrape manager stopped")
return err
},
func(err error) {
// Scrape manager needs to be stopped before closing the local TSDB
// so that it doesn't try to write samples to a closed storage.
level.Info(logger).Log("msg", "Stopping scrape manager...")
scrapeManager.Stop()
},
)
}
启动的核心语句:
# 启动动态发现
discoveryManagerScrape.Run()
# 启动目标抓取
scrapeManager.Run(discoveryManagerScrape.SyncCh())
discoveryManagerScrape.SyncCh()作为参数传递给scrapeManager.Run,来看看它的实现:
// SyncCh returns a read only channel used by all the clients to receive target updates.
func (m *Manager) SyncCh() <-chan map[string][]*targetgroup.Group {
return m.syncCh
}
实际上,是将discoveryManagerScrape和scrapeManager通过map[string][]*targetgroup.Groupchannel 连接了起来,也就是discoveryManagerScrape动态发现的目标通过这个channel,同步给scrapeManager,scrapeManager负责抓取。
我们来做一个小结:

其实,就是两个goroutine之间通过channel通信。
接下来,让我们看看scrapeManager.Run里面的实现:
// Run receives and saves target set updates and triggers the scraping loops reloading.
// Reloading happens in the background so that it doesn't block receiving targets updates.
func (m *Manager) Run(tsets <-chan map[string][]*targetgroup.Group) error {
go m.reloader()
for {
select {
case ts := <-tsets:
m.updateTsets(ts)
select {
case m.triggerReload <- struct{}{}:
default:
}
case <-m.graceShut:
return nil
}
}
}
核心是一个for循环,channel tsets(map[string][]*targetgroup.Group)等待动态发现传递的目标,调用m.updateTsets(ts)更新抓取的目标,设置reload信号m.triggerReload <- struct{}{},周而复始,先来看看m.updateTsets(ts)坐了什么操作:
func (m *Manager) updateTsets(tsets map[string][]*targetgroup.Group) {
m.mtxScrape.Lock()
m.targetSets = tsets
m.mtxScrape.Unlock()
}
没错,很简单,将监控的目标进行了更新。再来,看看Manager结构体的定义:
type Manager struct {
logger log.Logger
append storage.Appendable
graceShut chan struct{}
jitterSeed uint64 // Global jitterSeed seed is used to spread scrape workload across HA setup.
mtxScrape sync.Mutex // Guards the fields below.
scrapeConfigs map[string]*config.ScrapeConfig
scrapePools map[string]*scrapePool
targetSets map[string][]*targetgroup.Group
triggerReload chan struct{}
}
可以看到跟抓取有关的三个字段为:
scrapeConfigs map[string]*config.ScrapeConfig
scrapePools map[string]*scrapePool
targetSets map[string][]*targetgroup.Group
现在,discoveryManagerScrape通过channel将抓取的目标传递过来,scrapeManager内部到底是怎样转化成最后的HTTP请求呢?
scrapeManager.Run有一个重要的语句go m.reloader(),并在接收目标后设置了triggerReload
func (m *Manager) reloader() {
ticker := time.NewTicker(5 * time.Second)
defer ticker.Stop()
for {
select {
case <-m.graceShut:
return
case <-ticker.C:
select {
case <-m.triggerReload:
m.reload()
case <-m.graceShut:
return
}
}
}
}
Prometheus server每隔5秒,检查triggerReload channel,调用m.reload()
func (m *Manager) reload() {
m.mtxScrape.Lock()
var wg sync.WaitGroup
for setName, groups := range m.targetSets {
if _, ok := m.scrapePools[setName]; !ok {
scrapeConfig, ok := m.scrapeConfigs[setName]
if !ok {
level.Error(m.logger).Log("msg", "error reloading target set", "err", "invalid config id:"+setName)
continue
}
sp, err := newScrapePool(scrapeConfig, m.append, m.jitterSeed, log.With(m.logger, "scrape_pool", setName))
if err != nil {
level.Error(m.logger).Log("msg", "error creating new scrape pool", "err", err, "scrape_pool", setName)
continue
}
m.scrapePools[setName] = sp
}
wg.Add(1)
// Run the sync in parallel as these take a while and at high load can't catch up.
go func(sp *scrapePool, groups []*targetgroup.Group) {
sp.Sync(groups)
wg.Done()
}(m.scrapePools[setName], groups)
}
m.mtxScrape.Unlock()
wg.Wait()
}
这个方法完成了核心的转换,将目标转换成可以执行的任务,抽出核心业务我们可以得到这样的范式:
var wg sync.WaitGroup
for _, t := range tsets {
wg.Add(1)
go func(t int) {
wg.Done()
}(t)
}
wg.Wait()
回到业务上,我们发现targetSets、scrapeConfigs和scrapePools进行了完美的转换,如果scrapePools没有setName,并且scrapeConfigs有相应的配置,则调用newScrapePool创建scrapePool,更新到Manager,最后将scrapePool和[]*targetgroup.Group传递给匿名函数,完成sp.Sync(groups)调用,然我们继续跟踪Sync方法:
func (sp *scrapePool) Sync(tgs []*targetgroup.Group) {
sp.mtx.Lock()
defer sp.mtx.Unlock()
start := time.Now()
sp.targetMtx.Lock()
var all []*Target
sp.droppedTargets = []*Target{}
for _, tg := range tgs {
targets, err := targetsFromGroup(tg, sp.config)
if err != nil {
level.Error(sp.logger).Log("msg", "creating targets failed", "err", err)
continue
}
for _, t := range targets {
if t.Labels().Len() > 0 {
all = append(all, t)
} else if t.DiscoveredLabels().Len() > 0 {
sp.droppedTargets = append(sp.droppedTargets, t)
}
}
}
sp.targetMtx.Unlock()
sp.sync(all)
targetSyncIntervalLength.WithLabelValues(sp.config.JobName).Observe(
time.Since(start).Seconds(),
)
targetScrapePoolSyncsCounter.WithLabelValues(sp.config.JobName).Inc()
}
Sync方法的核心有两个调用:
# 将Group转化成Target列表
targets, err := targetsFromGroup(tg, sp.config)
# 同步
sp.sync(all)
Target的定义如下:
type Target struct {
// Labels before any processing.
discoveredLabels labels.Labels
// Any labels that are added to this target and its metrics.
labels labels.Labels
// Additional URL parameters that are part of the target URL.
params url.Values
mtx sync.RWMutex
lastError error
lastScrape time.Time
lastScrapeDuration time.Duration
health TargetHealth
metadata MetricMetadataStore
}
这就是要抓取一个目标的所有配置,基本信息都包含在这里面了,现在配置转化成了可以执行的目标,我们看看sp.sync的具体实现:
// sync takes a list of potentially duplicated targets, deduplicates them, starts
// scrape loops for new targets, and stops scrape loops for disappeared targets.
// It returns after all stopped scrape loops terminated.
func (sp *scrapePool) sync(targets []*Target) {
var (
uniqueLoops = make(map[uint64]loop)
interval = time.Duration(sp.config.ScrapeInterval)
timeout = time.Duration(sp.config.ScrapeTimeout)
limit = int(sp.config.SampleLimit)
honorLabels = sp.config.HonorLabels
honorTimestamps = sp.config.HonorTimestamps
mrc = sp.config.MetricRelabelConfigs
)
sp.targetMtx.Lock()
for _, t := range targets {
hash := t.hash()
if _, ok := sp.activeTargets[hash]; !ok {
s := &targetScraper{Target: t, client: sp.client, timeout: timeout}
l := sp.newLoop(scrapeLoopOptions{
target: t,
scraper: s,
limit: limit,
honorLabels: honorLabels,
honorTimestamps: honorTimestamps,
mrc: mrc,
})
sp.activeTargets[hash] = t
sp.loops[hash] = l
uniqueLoops[hash] = l
} else {
// This might be a duplicated target.
if _, ok := uniqueLoops[hash]; !ok {
uniqueLoops[hash] = nil
}
// Need to keep the most updated labels information
// for displaying it in the Service Discovery web page.
sp.activeTargets[hash].SetDiscoveredLabels(t.DiscoveredLabels())
}
}
var wg sync.WaitGroup
// Stop and remove old targets and scraper loops.
for hash := range sp.activeTargets {
if _, ok := uniqueLoops[hash]; !ok {
wg.Add(1)
go func(l loop) {
l.stop()
wg.Done()
}(sp.loops[hash])
delete(sp.loops, hash)
delete(sp.activeTargets, hash)
}
}
sp.targetMtx.Unlock()
targetScrapePoolTargetsAdded.WithLabelValues(sp.config.JobName).Set(float64(len(uniqueLoops)))
forcedErr := sp.refreshTargetLimitErr()
for _, l := range sp.loops {
l.setForcedError(forcedErr)
}
for _, l := range uniqueLoops {
if l != nil {
go l.run(interval, timeout, nil)
}
}
// Wait for all potentially stopped scrapers to terminate.
// This covers the case of flapping targets. If the server is under high load, a new scraper
// may be active and tries to insert. The old scraper that didn't terminate yet could still
// be inserting a previous sample set.
wg.Wait()
}
这个方法现将Target转换成Loop,然后调用go l.run(interval, timeout, nil)开始抓取:
type loop interface {
run(interval, timeout time.Duration, errc chan<- error)
setForcedError(err error)
stop()
getCache() *scrapeCache
disableEndOfRunStalenessMarkers()
}
loop是一个interface,只要实现相应的方法都是loop。
run方法核心的在于调用scraper的scrape方法和report方法,scrape负责抓取,report负责数据上报,进行下一步的存储,scraper的定义如下:
type scraper interface {
scrape(ctx context.Context, w io.Writer) (string, error)
Report(start time.Time, dur time.Duration, err error)
offset(interval time.Duration, jitterSeed uint64) time.Duration
}
具体实现的是targetScraper,定义如下:
type targetScraper struct {
*Target
client *http.Client
req *http.Request
timeout time.Duration
gzipr *gzip.Reader
buf *bufio.Reader
}
func (s *targetScraper) scrape(ctx context.Context, w io.Writer) (string, error) {
if s.req == nil {
req, err := http.NewRequest("GET", s.URL().String(), nil)
if err != nil {
return "", err
}
req.Header.Add("Accept", acceptHeader)
req.Header.Add("Accept-Encoding", "gzip")
req.Header.Set("User-Agent", userAgentHeader)
req.Header.Set("X-Prometheus-Scrape-Timeout-Seconds", fmt.Sprintf("%f", s.timeout.Seconds()))
s.req = req
}
resp, err := s.client.Do(s.req.WithContext(ctx))
if err != nil {
return "", err
}
defer func() {
io.Copy(ioutil.Discard, resp.Body)
resp.Body.Close()
}()
if resp.StatusCode != http.StatusOK {
return "", errors.Errorf("server returned HTTP status %s", resp.Status)
}
if resp.Header.Get("Content-Encoding") != "gzip" {
_, err = io.Copy(w, resp.Body)
if err != nil {
return "", err
}
return resp.Header.Get("Content-Type"), nil
}
if s.gzipr == nil {
s.buf = bufio.NewReader(resp.Body)
s.gzipr, err = gzip.NewReader(s.buf)
if err != nil {
return "", err
}
} else {
s.buf.Reset(resp.Body)
if err = s.gzipr.Reset(s.buf); err != nil {
return "", err
}
}
_, err = io.Copy(w, s.gzipr)
s.gzipr.Close()
if err != nil {
return "", err
}
return resp.Header.Get("Content-Type"), nil
}
我们终于看到,最后的最后,抓取其实是一个HTTP请求。为了完成一个抓取,Prometheus server进行了复杂的转化过程,正是这种实现,才让Prometheus拥有动态管理抓取目标的能力,我们大概来回忆一下这个转化过程:
Group --------
| \
| -> scrapePool -> pool -> scraper
| /
Tatget -------
终于,我们把Prometheus server的抓取过程翻了个底朝天,裨益甚多。
那么数据抓取过来就是存储、分析和展示了,下一篇我们开始研究存储。